Main AI Concepts
June 2024 update:
Click on the image below
to see my current work at Substack.
That work is a continuation of the articles here
on aibluedot.com and the work we do at sd-ai.org

Please subscribe so that you can receive updates
and new articles in your inbox. They are always free.
Original: 02/01/20
Revised: 09/13/20 , Revised: 06/08/21
This is a long article, as it presents most of the concepts on which all of the subsequent articles depend. Instead of going the historical route, or the traditional gradual route taken by teachers of AI courses, we will aim in a straight line at one of the most important accomplishments in AI and the one that raised the most eyebrows. We want to understand as much of this accomplishment as possible, because it shows a path to very strong AI systems and even a potential path to AGI (Artificial General Intelligence), the intelligence on par with human intelligence. The AI technique used in that accomplishment is called Deep Reinforcement Learning (DRL). In a nutshell, DRL is learning by trial and error with the help of neural networks.
 The accomplishment we are talking about is the development (using DRL) by Google's Deep Mind division, of its AlphaGo program, which program has defeated the reigning champion at the game of Go. It is undoubtedly the most talked-about success in AI. Since Go originated in ancient China and it is much revered in China, the effect of the AlphaGo win raised consciousness about AI to higher levels in China than in the U.S.. Some call AlphaGo's match with Lee Sedol, "China's Sputnik moment", the event that spurred China to embark on its ambitious plan to catch up with the U.S. in AI (we will analyze the emerging global competition between the U.S. and China in a full topic article).
The accomplishment we are talking about is the development (using DRL) by Google's Deep Mind division, of its AlphaGo program, which program has defeated the reigning champion at the game of Go. It is undoubtedly the most talked-about success in AI. Since Go originated in ancient China and it is much revered in China, the effect of the AlphaGo win raised consciousness about AI to higher levels in China than in the U.S.. Some call AlphaGo's match with Lee Sedol, "China's Sputnik moment", the event that spurred China to embark on its ambitious plan to catch up with the U.S. in AI (we will analyze the emerging global competition between the U.S. and China in a full topic article).
 Why is this game playing success of AI so important? There are three games that have captured our imagination and which continue to provide us with unparalleled intellectual satisfaction: Chess, Go, and Bridge. The best players of these games obviously have a higher than average intelligence, and creating AI that can beat these players is a very effective motivation to make progress in AI . Bridge is different from Chess and Go in one essential aspect. The players in Chess and Go both see the entire state of the game at any particular time. The players at Bridge, as in most card games, only see a partial state and a big part of the game is to infer the status of the unseen cards, i.e., which player has which cards. In game theory, Bridge is referred to as an incomplete information game. Incomplete information games/situations arise in many social settings, while complete information games/situations are more common in economic settings. It is the social aspect that gives Bridge a particular charm. Incomplete information games present a different set of issues to tackle computationally and indeed, there has been less work in AI for Bridge. This will certainly change in the future. On a final note, one should not confuse "incompleteness of information" with "difficulty" and infer that Bridge is more difficult for humans than the other two.
Why is this game playing success of AI so important? There are three games that have captured our imagination and which continue to provide us with unparalleled intellectual satisfaction: Chess, Go, and Bridge. The best players of these games obviously have a higher than average intelligence, and creating AI that can beat these players is a very effective motivation to make progress in AI . Bridge is different from Chess and Go in one essential aspect. The players in Chess and Go both see the entire state of the game at any particular time. The players at Bridge, as in most card games, only see a partial state and a big part of the game is to infer the status of the unseen cards, i.e., which player has which cards. In game theory, Bridge is referred to as an incomplete information game. Incomplete information games/situations arise in many social settings, while complete information games/situations are more common in economic settings. It is the social aspect that gives Bridge a particular charm. Incomplete information games present a different set of issues to tackle computationally and indeed, there has been less work in AI for Bridge. This will certainly change in the future. On a final note, one should not confuse "incompleteness of information" with "difficulty" and infer that Bridge is more difficult for humans than the other two.
 This leaves Chess and Go as practical targets for AI development. In 1996 IBM's Deep Blue program beat the reigning Chess champion Gary Kasparov and that was a watershed moment. First thing that comes to mind when you think of an AI player of Chess and Go is to design a player that searches ALL the possible moves in any situation and selects the move with the best outcome. The number of moves in Chess and Go is obviously finite, but both are huge numbers, and there is no practical way to search all the moves. Therefore, both Deep Blue and Alpha Go had to use more sophisticated techniques. Go is the more demanding one to tackle with AI, the number of possible moves being higher than in Chess. The reason we target the deep reinforcement learning (DRL) technique in this article, it is because this is the technique used by Google's AlphaGo program.
This leaves Chess and Go as practical targets for AI development. In 1996 IBM's Deep Blue program beat the reigning Chess champion Gary Kasparov and that was a watershed moment. First thing that comes to mind when you think of an AI player of Chess and Go is to design a player that searches ALL the possible moves in any situation and selects the move with the best outcome. The number of moves in Chess and Go is obviously finite, but both are huge numbers, and there is no practical way to search all the moves. Therefore, both Deep Blue and Alpha Go had to use more sophisticated techniques. Go is the more demanding one to tackle with AI, the number of possible moves being higher than in Chess. The reason we target the deep reinforcement learning (DRL) technique in this article, it is because this is the technique used by Google's AlphaGo program.
Rule-Based versus Statistical Learning
How did we get to this "Sputnik moment" of AI? So far we have used the term intelligence loosely, let's make it more precise so we can work with it. The intelligence of a system is always judged relative to the environment in which it functions. By the intelligence of a system we mean its ability to transform information gotten from its environment into an internal knowledge, continuously improving on this knowledge and using this internal knowledge for future interaction with its environment. Another way to say the same thing is that a system would have to show a capacity to learn from its environment and apply those lessons to achieve its goals, in order for it to possess intelligence.
 AI started as a quest to understand and reproduce the rules of human intelligence. Although that quest did lead to the development of useful expert systems, it was generally a disappointment. Based on the definition of intelligence above, an intelligent system must develop a knowledge based on observations about its environment; the knowledge in the case of a rule-based system would be the set of rules. But those rules were programmed into the system by humans, the systems would not learn the rules by themselves, which was a big handicap to their usefulness. Such a system would look to see if any of the rules already present in its knowledge base were applicable to the input and apply them to produce the output. So you could see that they would not satisfy our more stringent requirement for intelligence, because they would not learn their models from their environment on their own.
AI started as a quest to understand and reproduce the rules of human intelligence. Although that quest did lead to the development of useful expert systems, it was generally a disappointment. Based on the definition of intelligence above, an intelligent system must develop a knowledge based on observations about its environment; the knowledge in the case of a rule-based system would be the set of rules. But those rules were programmed into the system by humans, the systems would not learn the rules by themselves, which was a big handicap to their usefulness. Such a system would look to see if any of the rules already present in its knowledge base were applicable to the input and apply them to produce the output. So you could see that they would not satisfy our more stringent requirement for intelligence, because they would not learn their models from their environment on their own.
But reasoning based on logical rules is not the only way a system can function, and it was only when the rule-based approach had been replaced (mostly in the last 20 years or so) with a statistical learning from data that AI had become so extraordinarily successful. The success of these AI systems is mainly due to the availability of large amounts of data from which they can learn and increased computer power to store and process this data. At the same time, powerful algorithms for statistical learning from these large amounts of data have been developed and they are our focus below. The history of this success of AI is very short, here is a good part of it:
Machine Learning and Deep Learning
Although AI is becoming more of a multidisciplinary field, we will be considering AI as a specialized field of Computer Science. Nowadays, when people refer to AI as a discipline they actually mean a smaller part of AI which has had the most remarkable success, Deep Learning. Deep Learning is a subset of a larger set of techniques known as Machine Learning ; you will hear both terms in the following discussions. The relationship between these 3 main fields of AI is captured in the following diagram, a good diagram to refer to in the following articles, when questions about terminology arise:

Say we want to use AI to derive insights and make predictions about a particular domain problem. The data from that domain is usually collected without much consideration for AI processing, and we say that data is in raw form. Here is an example of such data in raw form.

The dataset in the example is about various cars. The variables of the dataset are properties of cars: type, origin, engine size, price, and so on. In this example, the number of features is small, but many datasets contain hundreds, even thousands of such variables. Not all those variables capture the essence of the data, many times the captured features being redundant. For such datasets we have to transform the original variables into a smaller subset of more characteristic features. This phase, called feature extraction, can be quite involved. One reason why deep learning has been so successful is that deep learning algorithms can be given raw data, and they do the feature extraction on their own:

Regardless of feature extraction being performed or not, each data item is given to AI algorithms as a vector of features, for example a row vector of car data as in the car dataset above. A vector is nothing but an ordered set of elements, which elements can be in text form, or numerical form. Let's look at a typical AI algorithm, a classification algorithm. This algorithm is given labeled data; in the example below, each data item is labeled by the object it represents, i.e., we are telling the algorithm that some items are cars, others are bicycles, boats, and so on. We feed many such images to the algorithm and we hope that it learns a model which would allow it to predict what an object is when it is shown an unlabeled image:

Let's recall our definition of intelligence given above: the intelligence of a system is its ability to transform information obtained from its environment into an internal knowledge, continuously improve this knowledge and use this internal knowledge for future interaction with its environment. In Machine Learning and Deep Learning, the knowledge is stored in a statistical model. All AI systems we discuss will be based on these two types of techniques, so from now on for us knowledge equals model. AI systems use their models to make future predictions about new data that they are presented with.
Many of these predictions use machine learning and many other cases will continue to be developed with machine learning. But the spectacular success AI has had in the past 7 years has been due to advances in Deep Learning, i.e., learning based on artificial neural networks. This success has been so dominant that when AI is being mentioned today in the media, it is almost always referring to neural networks. Neural networks were proposed in 1986 but then went through periods of disappointments and setbacks, commonly referred to as AI winters. Three researchers in particular, are credited with the revival and the success of neural networks. We will encounter their work a number of times in our articles. They were awarded the 2018 Turing Prize, the most prestigious recognition in the field of Computer Science, and commonly referred to as the Nobel prize of Computer Science:
The Classical Example of Deep Learning:
Multi Layer Perceptrons
Deep Learning is based on neural networks. A neural network is a network of (artificial) neurons organized in layers and connected to each other in various ways. The first layer is the input layer, the last layer is the output layer and the layers in between are called hidden layers, because they are not seen , they are not interacting directly with the environment. A network is deep if it has at least 2 hidden layers, in addition to the input and the output layers. That's it, deep learning is nothing other than learning with these deep neural networks. And these deep neural networks account for the most spectacular results of AI nowadays.

What exactly are those connections between the various neurons? Let's look at the connections coming into one single neuron and see how this neuron processes the information carried by those connections. Each neuron holds a value, and each incoming connection is characterized by a certain weight w, a real number. The neuron applies a so-called activation function to the weighted sum of all its incoming connections, and it also adds in a free number b (not coming from any connections to other neurons), called a bias. Of course, b could be 0. Here is the complete picture:

How does such a neural network learn? The network starts with an initial set of weights and biases. The dataset which the network will learn is split into two sets, one set called the training set and another smaller set called the testing set. Both of these sets contain labeled examples, labeled here meaning that for each example, the correct outputs are known in advance to humans programming it. For each such example in the training set, the network calculates the error that it makes, the error being the difference between the outputs it generates (with its current weights) for the example, and the correct outputs. It then readjusts its weights through a back-propagation algorithm, beginning with the right layers and working its way towards the left layers. It does this readjusting of weights and biases for all the examples in the training set. The weights and the biases resulting from this iterative process, embody the model. After the model is built, its performance is measured on the remaining testing set. We will see this learning process at work on a classical example.
The inspiration for these artificial neural networks, and for the terminology used, is the human nervous system. The connections between neurons and the weights associated with these connections are abstractions of the synaptic transmission (later we will look at the neuron in more depth, but for now this is all we need):
We now look at a neural network that learns to recognize handwritten digits. It is a classical example that is used on many occasions and you can search the web for its many implementations, to deepen your understanding. It is also the simplest form of a neural network, called a multilayer perceptron. Although it is the simplest, it nevertheless showcases all the important concepts in deep learning. We use it as a means to pin down what we mean by knowledge and also as a vehicle to introduce all the AI concepts we will need. The data on which the network is trained is the MNIST dataset of handwritten digits, usually split into 60,000 training images and 10,000 testing images. Let's see how a network is trained to recognize handwritten digits:
The video above and the following one cover the most important aspects of deep neural networks and the payback for understanding them is very substantial; whenever AI will appear in the news you watch or in conversations you are having, you would have these very helpful videos in your mind and the mystery would be lifted. Now, you noticed that a few mathematical functions sneaked into the previous video. Although the math is not absolutely necessary to understand the rest of the article, these functions may be of help, now and later: Math
The gradient descent is then used by the backpropagation algorithm, the best known algorithm to train the feedforward neural networks we have looked at so far; it can be used for more complex network architectures, not just the multilayer perceptrons. The backpropagation algorithm computes the gradient of the loss function with respect to each weight by the chain rule, moving backwards one layer at a time from the output layer through the hidden layers. If you recall the chain rule from calculus, the derivative of the composition of two functions is the product of the derivatives of the components. If there are n hidden layers in the network, there will be n such multiplications. This is the main challenge with backpropagation, the gradients tend to become very small and even vanish as the algorithm moves backwards towards the input layer. Simple minded as it may sound, the idea of replacing sigmoidal functions with the RELU function as the main activation function has dramatically changed the effectiveness of backpropagation. All this, and much more, is explained in the following video, which represents a worthy payback for all the efforts the reader has made so far to understand deep learning:
Other Types of Neural Networks
The neural network we saw in the classical example is a very simple neural network. There are other more complicated networks that are being used for a variety of purposes; the sky seems to be the limit. In some of these networks the information is allowed to propagate backwards or be temporarily stored in its neurons, and so on. These networks are not necessary to understand in order to follow the rest of the articles. But if you are interested, you may want to look up Convolutional networks, Residual Neural Networks and Long Short-Term Memory networks. They are more difficult to train and require some experience in setting up properly. Convolutional nets and residual nets have been used in the development of the AlphaGo and AlphaGo Zero.

Most interesting applications require combinations of these types of networks. How are they built? What kind of architecture do you choose among the many options you have seen above? In other words, how many layers, what types of layers, how many neurons on which layer? There is no set answer and it is more art and experience with what works than a science of architecture. Of course, you may ask the computer to experiment itself with different architectures but the time it takes to run such experiments is usually too long for most practical problems. Here is a beautiful simulation of a few of these network architectures, for the same problem of handwritten digit recognition.
Deep Reinforcement Learning
Machine learning uses three main methods of learning: supervised, unsupervised, and reinforcement learning. In supervised learning a model is learned by looking at data which is labeled by humans while in unsupervised learning the model is learned by recognizing general patterns in unlabeled data. Reinforcement learning (RL), with or without deep networks, is a more technical way of learning and there is no skimming the surface. It may sound mathematically more difficult, but the motivations are usually very simple to grasp. RL is used for systems which have to learn in a sequence of steps. As opposed to supervised learning, where the outputs of the system are predictions of values based on examples presented, in RL the outputs of the system are actions which are then criticized by the environment, changing states and returning a reward. The system is free to choose certain actions and memorize what actions have led to better rewards. You may think of RL as being trial and error; Deep Reinforcement Learning is RL done with deep neural networks. Here is a succinct presentation of the main concepts:
AlphaGo and AlphaGo Zero
Now that the principles are familiar, we have reached the point where you could appreciate how important the achievement of a particular DRL-based system was in beating the world champion at Go. We are mentioning this in some other places, but it is worth repeating that because Go is an ancient and revered game in China, the success of AlphaGo was instrumental in considerably raising awareness of AI in China. We have not matched that awareness at all in the U.S..
While the success of AlphaGo has been the shock event that took everyone by surprise, it is newer versions of AlphaGo, named AlphaGo Zero and Alpha Zero, that are even more remarkable in their implications. AlphaGo Zero beat AlphaGo consistently, and it did not use a database of human played games to learn from. It learned by repeatedly playing games by itself. This AI has such strong pattern recognition abilities that it can learn how to play not just Go but other games, just by playing them repeatedly without human labeling of previous moves or games. Alpha Zero in turn can learn to play not just Go but Chess as well. For many, including researchers at DeepMind, this represents a potential direction to AGI.
Just like AlphaGo Zero learned to play Go without being given games previously played by humans, Alpha Zero learned to play chess, also without studying any chess games previously played by humans; within hours it reached a level of expertize enough to beat Starfish 8, the best computer-based chess playing software, winning 28 of the games, tying 72 games and losing no games. It showed a remarkable creativity, using new strategies unknown to humans up to that point.
Here is the technical description of all the components of this newer version of DeepMind's Alpha system, given by its chief architect. Other than the two deep networks (called value and policy), you would have to read up on a particularly effective method of searching graphs, the Monte Carlo Tree Search (MCTS) method, if you wish to understand these programs at a deeper level:
We have seen that AlphaGo Zero and Alpha Zero use less resources and less complex architectures than AlphaGo, so they apparently achieve something unheard of before. In all our discussions so far, the assumption has been that the success of AI is due more to massive data sets and less to the algorithms which learn from these data sets. Is there a possible paradigm shift in the case of these new algorithms in that they seem to take precedence over data? At first sight, the algorithms are given only the rules of a game. But in fact the algorithms do generate large amounts of data (games) and the learning from that data is still statistical. Does the fact that their data is generated instead of taken from the outside alter our assumption that data prevails over algorithms? How much of this can be generalized? How many situations do we find in real life where simple rules can be discovered? And even if they are discovered, will the "game" behind such rules have as much conceptual integrity to ensure good convergence properties for learning, as the game of Go or Chess? There is an entire class of AI systems called Generative Adversarial Networks (GANs) which use two networks, one generating data and the other one discriminating against this generation; AlphaZero can be looked at as such a GAN, as shown in the article Demystifying AlphaGo Zero as AlphaGo GAN.
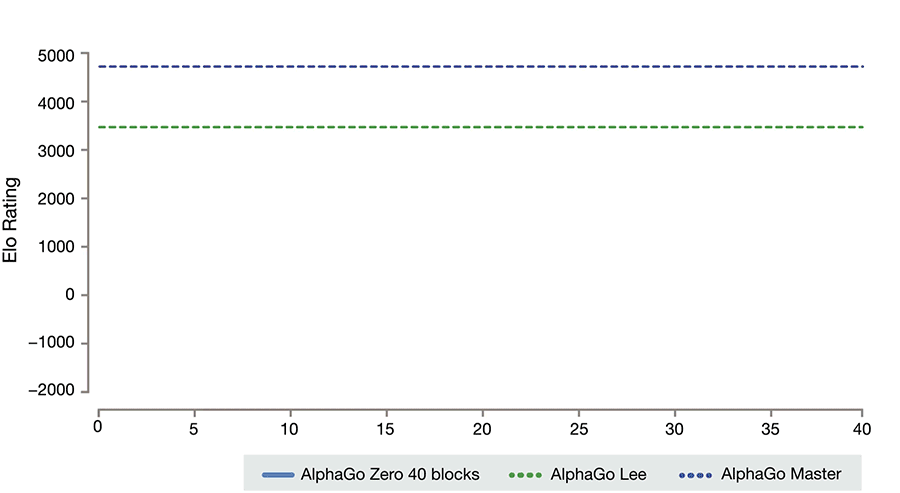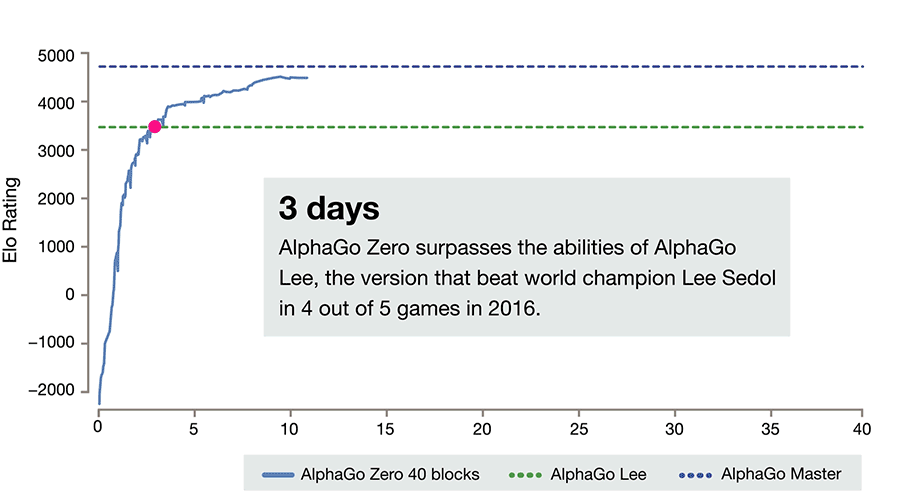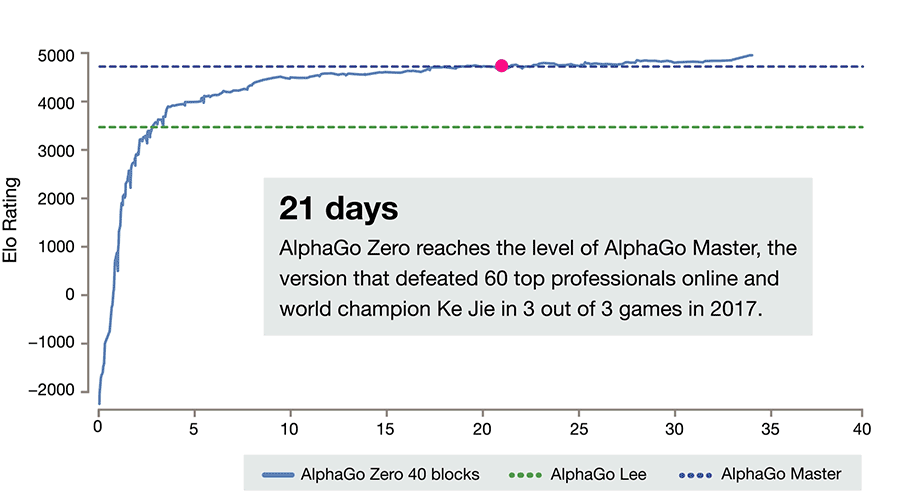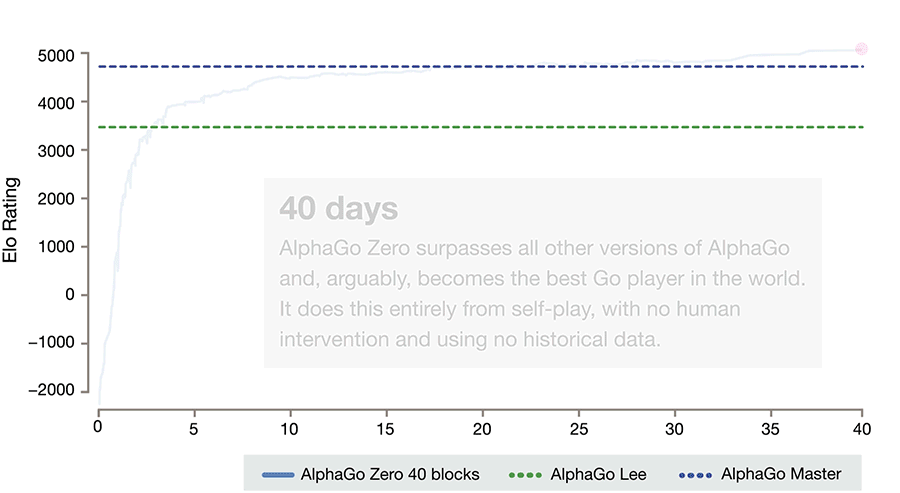
We have covered the concepts behind the current AI enough to allow us to continue on. In the following two articles, we will look at the different types of AI, as they relate (or not relate) to human intelligence. Two such types are Artificial General Intelligence (AGI), the intelligence on par with human intelligence, and a type which is not in common usage and which we will call Artificial Wide Intelligence (AWI); you can look at Google and Facebook as being such systems until we make the term AWI more precise. DeepMind's ambition to make progress towards AGI is clear. The achievements are undeniable. The implications of their work will certainly be analyzed and new methods will be developed, maybe in the direction of discovering the rules behind any particular domain of study, which would revive the old approach to AI, based on rules. Since our focus is more on AWI systems, which work on large graphs and are housed in large data centers, an obvious question pops up, and we should ask it while DeepMind's work is fresh in our minds: what would happen if a system like the one built by DeepMind, enhanced with abilities of discovering rules, would be let loose, by design or by accident, inside one of these AWI systems?
The Developers of AI
 Who are these people that create AI? There are two professional groups working in AI: data scientists and machine learning (ML) engineers .
Who are these people that create AI? There are two professional groups working in AI: data scientists and machine learning (ML) engineers .
Data scientists train in mathematics/statistics and how to understand and interpret data; they must understand the business objectives and how to prototype a model solving those objectives. ML engineers train in software engineering and use machine learning libraries to transform those prototypes into production grade models. They are also skilled at querying/storing/processing very large data sets, distributed over multiple servers, sometimes thousands of servers. Of course, some of the skills and responsibilities of individuals within these two groups sometimes overlap. These skill sets require many years of study and practice and this is one of the main problems for doing AI in the U.S.. We do not have an adequate supply of data scientists and ML engineers in the U.S.. The competition for finding them, especially between U.S. and China, is fierce and will grow fiercer.
There are a number of conferences around the world where these AI professionals get together with researchers in the AI field to discuss current and future developments of AI. Below you can see some of these forthcoming conferences in AI, shown on a rotating projection of the 3-D blue dot.
( The 3-D globe, launched when you click on the image below, is available in most, but not all browsers; if you can see it, great; if your computer is behind a company perimeter firewall, you may not be able to see it; however, from home you should be OK. You can navigate the globe by dragging it with the mouse to the location you want, or by swiping it, on your mobile. You can zoom in and out, on both desktop and mobile, by pinching it for example. A click or tap on a conference marker will open up the website with information about that conference. On the desktop, a left double-click anywhere outside the location markers will zoom in, and the globe will rotate faster. A right click will zoom back out and the globe's rotation will slow. Use the equivalent actions on the mobile. )

(Upcoming AI Conferences)

AlphaGo Full Documentary (1.5 hours)